1. 서브페이지
2. 참고서적
Perl의 기본 초, 중, 고급 단계 기본 책 시리즈
- OReilly.Learning.Perl.5th.Edition.Jul.2008.eBook-DDU.pdf
- intermediate_perl_2nd_edition.pdf
- Mastering Perl, 2nd Edition.pdf
3. CPAN 설정
# cpan repository 변경 o conf urllist -> 현재 설정되어 있는 미러의 사이트목록 o conf init urllist -> 현재 설정되어 있는 미러의 사이트목록 초기화 o conf urllist unshift URL -> URL을 미러로 등록한다. o conf commit -> 설정내용을 등록 (안하면 말짱 황~) # install yes option o conf build_requires_install_policy yes o conf prerequisites_policy follow o conf commit
4. 변수사용
4.1. 배열
# 배열 카운트
my @arr1 = (1,2,3,4);
print "Count : ", scalar @arr1, "\n";
print "Count : ", $#arr1, "\n";
# 배열관련 함수들
my @arr2 = (1,2,3,4,5);
push(@arr2, 6); push(@arr2, 7);
print join(", ", @arr2), "\n";
pop(@arr2); pop(@arr2);
print join(", ", @arr2), "\n";
shift(@arr2); shift(@arr2);
print join(", ", @arr2), "\n";
unshift(@arr2, 1); unshift(@arr2, 2);
print join(", ", @arr2), "\n";
#중복 제거
my @data = (1,2,3,4,5,1,2,7,8,'a', 'b', 'a');
my @unique1 = do { my %seen; grep { !$seen{$_}++ } @data }; # 순서 유지
my @unique2 = keys { map { $_ => 1 } @data }; # 순서 상관없이
print "@unique1\n";
print "@unique2\n";
4.2. 해쉬
# Hash의 모든 항목 출력
my %HashVar = (
test1 => "1",
test2 => "2",
test3 => "3",
);
while( my ($key, $val) = each(%HashVar) )
{
print "$key -> $val\n";
}
#---------------------------------------------------#
# Hash
#---------------------------------------------------#
print "\n---------------------------------------------------------\n";
print "** Hash";
print "\n---------------------------------------------------------\n";
my %Info = (
'test1' => '123',
'test2' => '456','test3' => [7,8,9],
# hash에 hash연결
'test4' => {
'id' => 10,
'pass' => 11,
'sub' => {
'val' => 100,
}
},
);
$Info{'test5'} = {
'val1' => 123,
val2 => 1235678,
};
# Hash에 배열 붙이기
my @ArTest = (1, 2, 3, 4, 5, 6, 7);
$Info{'test6'} = \@ArTest;
$Info{'test7'} = [];
push($Info{'test7'}, 10);
push($Info{'test7'}, 11);
push($Info{'test7'}, 12);
print "test1 : ", $Info{'test1'}, "\n";
print "test2 : ", $Info{'test2'}, "\n";
print "test3 : ", join(",",@{ $Info{'test3'} }), "\n";
print "test4 : ", $Info{'test4'}->{'id'}, "\n";
print "test4 : ", $Info{'test4'}->{pass}, "\n";
print "test4 : ", $Info{'test4'}->{sub}->{val}, "\n";
print "test5 : ", $Info{test5}->{val1}, "\n";
print "test5 : ", $Info{test5}->{val2}, "\n";
print "test6 : ", join(",",@{ $Info{'test6'} }), "\n";
print "test7 : ", join(",",@{ $Info{'test7'} }), "\n";
print "\n\n";
print Dumper %Info;
#---------------------------------------------------#
# Hash in Arrary
#---------------------------------------------------#
print "\n---------------------------------------------------------\n";
print "** Hash in Arrary";
print "\n---------------------------------------------------------\n";
my @server_data = (
{ id=>'calmmass', pass=>'ucess', ip=>'203.223.233.231' },
{ id=>'mass' , pass=>'ucess', ip=>'203.223.233.232' },
{ id=>'mas12' , pass=>'ucess', ip=>'203.223.233.233' },
{ id=>'ma2345' , pass=>'ucess', ip=>'203.223.233.234' },
);
foreach my $ip ( @server_data )
{
printf "ID : %10s PW : %10s IP : %16s \n", $ip->{id}, $ip->{pass}, $ip->{ip};
}
print "\n\n";
my %server_data = (
'203.223.233.231'=> { id=>'calmmass', pass=>'ucess', },
'203.223.233.232'=> { id=>'mass' , pass=>'ucess', },
'203.223.233.233'=> { id=>'mas12' , pass=>'ucess', },
'203.223.233.234'=> { id=>'ma2345' , pass=>'ucess', },
);
foreach my $ip ( keys %server_data )
{
printf "ID : %10s PW : %10s IP : %16s \n", $server_data{$ip}->{id}, $server_data{$ip}->{pass}, $ip;
}print "\n\n";
print Dumper @server_data;
5. 자주 쓰는 코드
한동안 perl을 안쓰다가 쓸때가 되면 항상 생각이 나지 않는 것들 ;;
5.1. OOP 템플릿
#!/usr/bin/perl
# 스크립트 실행을 위해 다음 명령 실행 필요
# > cpan install [module_name]
#========================================================#
# Main
#========================================================#
package main;
{
my $agent = Agent->new();
# 초기화
$agent->Init();
# 처리
$agent->DoSomething();
# 정리
$agent->Uninit();
}
#========================================================#
# Agent Class
#========================================================#
package Agent;
{
use Data::Dumper qw(Dumper);
#========================================================#
# 생성자
#========================================================#
sub new()
{
my ($class) = @_;
my $self = {};
bless $self, $class;
Expand
source
return $self;
}
#========================================================#
# 초기화
#========================================================#
sub Init()
{
my $self = shift;
}
#========================================================#
# 처리
#========================================================#
sub DoSomething()
{
my $self = shift;
}
#========================================================#
# 정리
#========================================================#
sub Uninit()
{
my $self = shift;
}
}
5.2. Time 관련
# 현재 시간 가져오기
my ($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime(time);
$year += 1900;
$mon += 1;
my $strNow = sprintf("%d-%02d-%02d", $year, $mon, $mday);
# 소요시간 체크하기
use Time::HiRes qw/gettimeofday tv_interval/;
my $start = [gettimeofday];
my $end = [gettimeofday];
printf("Elapsed Time : %.6f s", tv_interval($start, $end));
# DateTime 모듈 사용하기
use DateTime;
use Data::Dumper;
# Set Time Zone
my $dtLocal = DateTime->now->set_time_zone('Asia/Seoul');
my $dtUTC = DateTime->now();
my $dt = DateTime->new(
year => 1964,
month => 10,
day => 16,
hour => 16,
minute => 12,
second => 47,
nanosecond => 500000000,
time_zone => 'Asia/Taipei',
);
# 시간 출력
print $dtLocal->datetime() , "\n";
print $dtLocal->ymd. " ". $dtLocal->hms, "\n";
print $dtLocal->ymd(''). " ". $dtLocal->hms('-'), "\n";
# 시간 더하기. 초는 seconds
print $dtLocal->add(hours => 2)->datetime(), "\n";
# 시간차 구하기 - DateTime::Duration
my $timespan = $dtLocal - $dtUTC;
print $timespan->{minutes}, "\n";
print Dumper $timespan;
# Datetime 시간 차이 구하기
use DateTime;
use DateTime::Format::Strptime;
use DateTime::Format::Duration;
use DateTime::Format::MySQL;
use Data::Dumper qw(Dumper);
# Test 1
print "Time Compare1\n\n";
my $strp = DateTime::Format::Strptime->new(
pattern => '%F%n%T',
time_zone => 'Asia/Seoul',
);
my $TimeCompareStart = $strp->parse_datetime('2015-05-18 12:00:00');
my $TimeCompareEnd = $strp->parse_datetime('2015-05-18 13:00:20');
print $TimeCompareStart->ymd. " ". $TimeCompareStart->hms, "\n";
print $TimeCompareEnd->ymd. " ". $TimeCompareEnd->hms, "\n";
print DateTime->compare( $TimeCompareStart, $TimeCompareEnd ), "\n";
my $tmSpan = $TimeCompareEnd - $TimeCompareStart;
print "Time span (sec) : ", ($tmSpan->{minutes} * 60) + $tmSpan->{seconds}, "\n\n\n";
print Dumper $tmSpan, "\n";
# Test2
print "Time Difference\n\n";
my $dt1 = DateTime::Format::MySQL->parse_datetime("2015-05-19 12:00:00");
my $dt2 = DateTime::Format::MySQL->parse_datetime("2015-05-19 12:05:00");
my $duration = $dt1 - $dt2;
my $format = DateTime::Format::Duration->new(
pattern => '%F %T'
);
print $format->format_duration($duration);
# unix 시간 변환. Unix -> DateTime
use DateTime;
use DateTime::Format::Epoch::Unix;
use DateTime::Format::Strptime;
my $dt = DateTime::Format::Epoch::Unix->parse_datetime(1420766636);
print $dt->ymd." ".$dt->hms,"\n\n";
# unix 시간 변환. DateTime -> Unix
print DateTime::Format::Epoch::Unix->format_datetime(DateTime->now());
5.3. 파일, 폴더, 경로 관련
# 폴더내의 모든 파일 가져오기. (recursive)
#!/usr/bin/perl
use File::Find;
find(\&readFunction, $dir);
sub readFunction()
{
print $File::Find::name, "\n";
}
# 폴더내의 파일 목록 가져오기
opendir(my $FP, ".");
my @FolderList = readdir($FP);
close($FP);
# 현재 경로 확인
use Cwd qw(abs_path);
my $abs_path = abs_path("Noname1.pl");
print $abs_path;
my $strCurPath = abs_path($0); # 현재 파일의 경로
$strCurPath = substr($strCurPath, 0, rindex($strCurPath, "/")); # Get Path
# 경로에서 파일명, 경로 가져오기
my $strFullPath = "D:\\02.JC\\JC_Dev\\perl\\Source\\Test\\Test.pl";
my $FileName = substr($strFullPath, rindex($strFullPath, "\\") + 1, length($strFullPath) - rindex($strFullPath,
"\\") + 1);
my $Path = substr($strFullPath, 0, rindex($strFullPath, "\\"));
print "FileName : $FileName\n";
print "Path : $Path\n";
# 파일 및 폴더 삭제
use File::Path qw(remove_tree);
unlink("text.txt");
remove_tree("TempFolder") or print "can not delete: $@";
# 파일 간단히 읽고 쓰기
use File::Slurp;
my @data1 = ('Test1', 1, 2, 3, 'Test2');
write_file("test.txt", join("\n", @data1));
my @data2 = ();
@data2 = read_file("test.txt");
print @data2;
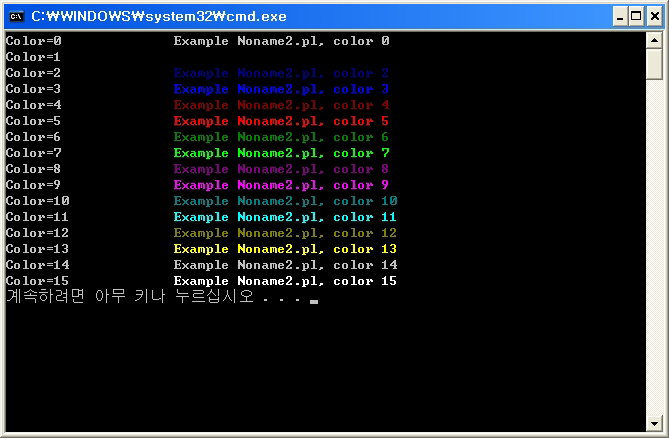
5.4. 콘솔 텍스트 컬러 출력
#!/usr/bin/perl
use Color::Output;
Color::Output::Init;
for(0..15)
{
cprint("Color=$_". (" " x (15 - length($_))) ."\x03" . $_ . "Example $0, color $_\x030\n");
}
cprint "\x037"; # 녹색
print "Test Text\n";
cprint "\x030"; # 원상태 변경
5.5. 문자열 처리
# text trim
$line =~ s/^\s+//g;
$line =~ s/\s+$//g;#============================================================================#
# 대소문자 변환. 열라 간담함 ㅋ
my $str = uc $strText # 대문자
my $str = lc $strText # 소문자
my $str = ucfirst $strText # 첫글자만 대문자
my $str = lcfirst $strText # 첫글자만 소문자
#============================================================================## 문자열 조작
# substr : substr EXPR,OFFSET,LENGTH,REPLACEMENT
my $s = "The black cat climbed the green tree";
my $color = substr $s, 4, 5; # black
my $middle = substr $s, 4, -11; # black cat climbed the
my $end = substr $s, 14; # climbed the green tree
my $tail = substr $s, -4; # tree
my $z = substr $s, -4, 2; # tr
my $name = 'fred';
substr($name, 4) = 'dy'; # $name is now 'freddy'
my $null = substr $name, 6, 2; # returns "" (no warning)
my $oops = substr $name, 7; # returns undef, with warning
substr($name, 7) = 'gap'; # raises an exception# split : split /PATTERN/,EXPR,LIMIT
my @listResult = split(/b/, 'abc');
print join(':', split(',', 'a,b,c,,,')), "\n";
print join(':', split(',', 'a,b,c,,,', -1)), "\n";# 문자열에서 2글자씩 출력하기
use YAML;
$string = "3765494567";
@test = unpack('A2' x (length($string) / 2), $string);
print Dump(\@test);
5.6. @INC 변수에 경로 추가
모듈 로드시 자동으로 확인하게 되는 @INC에 경로 추가로 넣기
#!/usr/bin/perl use strict; use warnings; use File::Basename qw(dirname); use Cwd qw(abs_path); use lib dirname(dirname abs_path $0) . '/lib'; use My::Math qw(add); print add(19, 23);
5.7. Print dump
use Data::Dumper; use YAML; my @temp = qw/1 2 3 4 5 6 7 8/; my %test2 = ( a => 1, b => 2); # Array print "** Array\n\n"; print Data::Dumper->Dump( [\@temp], [qw(*temp)] ); print "-" x 50, "\n"; print Dump(\@temp); print "-" x 50, "\n"; print Dumper @temp; print "-" x 50, "\n\n\n"; # Hash print "** Hash\n\n"; print Data::Dumper->Dump( [\%test2], [qw(*test2)] ); print "-" x 50, "\n"; print Dump(\%test2); print "-" x 50, "\n"; print Dumper %test2;
5.8. 암호화
# Blowfish
use Crypt::CBC;
$cipher = Crypt::CBC->new( -key => 'my secret key',
-cipher => 'Blowfish'
);
$ciphertext = $cipher->encrypt("Test");
$plaintext = $cipher->decrypt($ciphertext);
print $ciphertext, "\n";
print $plaintext, "\n";# AES
use Crypt::CBC;
my $key = 'little brown mouse';
my $cipher = Crypt::CBC->new(
-key => 'bobkey',
-keylength => '256',
-cipher => "Crypt::OpenSSL::AES"
);
my $encrypted = $cipher->encrypt_hex($key);
my $decrypted = $cipher->decrypt_hex($encrypted);
print "Encrypted : ", $encrypted, "\n";
print "Decrypted : ", $decrypted, "\n";
print "Decrypted2 : ",
$cipher->decrypt_hex('53616c7465645f5ffee73e573903eb14b6005f206008e868fda6dc3bfb9f74458cda03c05
b903826d982232836353171'), "\n";
5.9. Hash
# MD5 and sha1
use Digest::MD5 qw(md5 md5_hex);
use Digest::SHA1 qw(sha1 sha1_hex);
print md5_hex("update.officekeeper.co.kr"), "\n";
print sha1_hex("update.officekeeper.co.kr"), "\n";
5.10. 항목비교
# 트라이(trie)는 트리와 유사한 자료 구조로 주로 문자열 등에 대한 동적 집합 혹은 연관 배열을 저장합니다.
# 키 값의 전체가 아닌 일부만 비교하는데 사용되므로 매우 빠르게 비교를 수행합니다.
use Tree::Trie;
my $trie = Tree::Trie->new;
$trie->add(qw[
사람
사냥꾼
사슴
가자미
가재
가마
사재기
사계절
가마
가솔린
나무
나비
다다미
다슬기
사루만
가마꾼
나방
]);
my @all = $trie->lookup(q{});
my @ga_list = $trie->lookup("가");
my @gama_list = $trie->lookup("가마");
printf( "모든 데이터셋: %s\n", join( '--', @all ) );
printf( "가 : %s\n", join( '--', @ga_list ) );
printf( "가마 : %s\n", join( '--', @gama_list ) ); # Smart Match
my @CompareArr = (1,2,3,4,5);
my $iCompare = 1;
if ($iCompare ~~ @CompareArr)
{
print "Exist\n";
}
else
{
print "Not Exist\n";
}
5.11. Zip
use Archive::Zip qw( :ERROR_CODES :CONSTANTS );# Test data
mkdir("ZipTest1");
mkdir("ZipTest1\\SubZipTest1");
mkdir("ZipTest1\\SubZipTest2");
mkdir("ZipTest2");
open(my $FP, ">", "ZipTest1\\a.txt");
print $FP "ZipTest";
close($FP);
open(my $FP, ">", "ZipTest1\\b.txt");
print $FP "ZipTest";
close($FP);# Zip. 파일만 압축
{
my $zip = Archive::Zip->new();
$zip->addFile( { filename => "ZipTest1\\a.txt", zipName => 'a.txt' });
$zip->addFile( { filename => "ZipTest1\\b.txt", zipName => 'b.txt' });
# Save the Zip file
unless ( $zip->writeToFileNamed("ZipTest1.zip") == AZ_OK )
{
die 'write error';
}
}# Zip. 폴더 압축{
my $zip = Archive::Zip->new();
my $d = $zip->addDirectory('ZipTest1','ZipTest1');
$zip->addFile("ZipTest1\\a.txt");
$zip->addFile("ZipTest1\\b.txt");
my $d = $zip->addDirectory('ZipTest2','ZipTest2');
# Save the Zip file
unless ( $zip->writeToFileNamed("ZipTest2.zip") == AZ_OK )
{
die 'write error';
}
}
5.12. DB
mssql 접속 코드. mssql를 이용하려면 windows의 경우 odbc 설정을 해줘야 한다.
# mssql
use DBI;
my ($user_ms, $password_ms) = ('stxsecuser', 'secuserp4ss!');
my $dsn_ms = "DBI:ODBC:DSN=SERVER;uid=$user_ms;pwd=$password_ms;";
my $dbh_ms = DBI->connect($dsn_ms);
my $sth = $dbh_ms->prepare("SELECT * FROM `TB_Business_Database` WHERE `Alias` =
'__DB_PRODUCT_##__';");
$sth->execute();
while(my $ref = $sth->fetchrow_hashref())
{
}
$sth->finish();
$dbh_ms->disconnect();# mysql
use DBI;
my ($database, $hostname, $port, $user, $password) = ('DB-Common', '127.0.0.1', '3306', 'office',
'office@jiran');
my $dsn = "DBI:mysql:database=$database;host=$hostname;port=$port";
my $dbh = DBI->connect($dsn, $user, $password);
$dbh->do("SET NAMES EUCKR;");
my $sth = $dbh->prepare("SELECT * FROM `TB_Business_Database` WHERE `Alias` =
'__DB_PRODUCT_##__';");
$sth->execute();
while(my $ref = $sth->fetchrow_hashref())
{
}
$sth->finish();
$dbh->disconnect();
5.13. map
use Data::Dumper;
@names = qw(Foo Bar Baz);
@input_numbers = (1, 2, 4, 8, 16, 32, 64);# 배열 -> 배열
@invited2 = map {$_ => 1} @names;
print Dumper \@invited2, "\n\n";
@result = map { $_, 3 * $_ } @input_numbers;
print Dumper \@result, "\n\n";# 배열 -> 해쉬 변환
%invited1 = map {$_ => 1} @names;
print Dumper \%invited1;
print "\n\n";
%hash = map { $_, 3 * $_ } @input_numbers;
print Dumper \%hash, "\n\n";# 필요한 항목만 가져오기
@names = qw(Foo Bar Baz);
@invited = map { $_ =~ /^F/ ? ($_) : () } @names;
print "@invited\n\n";# 첫 글자만 대문자로 변경 출력
@myNames = ('jacob', 'alexander', 'ethan', 'andrew');
print join("\n", map{ucfirst} @myNames), "\n\n";# 반복문 없이 출력print "Some powers of two are:\n", map { ( 2 ** $_ ) . "\n"} 0..15;print "\n\n";